




近日,国家天文台白宇副研究员、刘继峰研究员基于LAMOST和SDSS数据库,利用机器学习的方法,开发天体分类器和恒星温度回归器,并把天体分类器应用到最新发布的Gaia DR2星表,揭示了Gaia DR2中天体类型组成。这是国际上使用最大样本开发的天体分类器和恒星温度回归器,该项研究成果已经被《天文学杂志》(AJ)接收,应用于Gaia DR2的最新结果已经发表在《天文和天体物理学研究》(2018,RAA,18,118)上。
近几年,科学技术进步推动的天文数据呈现指数增长,天文大数据时代已经到来。科学家们曾经使用的光谱分类方法,难以应对十亿计的测光巡天数据。曾经使用的多色分类方法,也随着颜色的增多而变得非常复杂,无法给出函数表达式,分类准确率低,污染严重。然而,二十世纪中叶发展起来的机器学习方法,能够有效的探测多维参数空间中隐藏的规律,帮助天文学家进行决策和预测。它的核心思想是教会计算机通过“经验”,而不是判据,对未知数据进行判断。
这里的“经验”,是指开发模型所需要的训练数据,它的准确性直接关系到最后产出的正确率。所以,光谱巡天数据被认为是理想的“经验”数据。国家重大科技基础设施郭守敬望远镜(LAMOST)巡天已经产出近千万量级的天体光谱,为科研人员开发机器学习模型提供了机遇。首先,科研人员合并LAMOST和SDSS的光谱分类结果;其次,结合可见光和红外巡天数据,获取这些天体的多色数据库;再次,测试不同的机器学习方法,找出效率最高的算法并开发天体分类器,通过不同巡天数据对分类器进行盲测,准确率为94%-99%;最后,依据光谱巡天给出的恒星温度,开发恒星温度回归器,使用其它巡天数据对回归器进行盲测,标准偏差为200K。此外,科研人员还把分类器应用于最新发表的Gaia DR2,发现其中大约98%为恒星,2%为星系和类星体,使用视差相对误差的判据可以得到非常纯净的恒星样本。该项研究成果对于天体大数据分析,Gaia DR2星表的合理应用有着重要的意义。
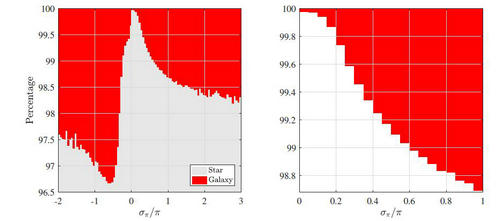
Gaia DR2中恒星所占百分比随视差相对误差的分布,右图为左图的放大。
附件下载: